

I’m not in San Jose this year. Gutted about that, if I'm honest.
GTC is the one event where the people building the physical layer of AI are all in the same building, and not being in the room stings. But I've pulled apart the full two-hour keynote, cross-referenced it against every press release NVIDIA dropped (twenty of them, simultaneously), and sourced every claim against the technical detail.
No PR.
No spin.
Just what was actually said, what shipped, and what it means for the people who build, buy, and fund GPU infrastructure.
Let’s get into it.
The GPU Audio Companion Issue #97
Want the GPU breakdown without the reading? The Audio Companion does it for you, but only if you’re subscribed. If you can’t see it below, click here to fix that.
[00] Watch The Keynote
[01] Vera Rubin: Seven Chips, Five Racks, One System
The centrepiece of GTC 2026 is the NVIDIA Vera Rubin platform, the successor to Grace Blackwell.

Seven new chips, all in full production, shipping to customers H2 2026. The full system operates as a single POD-scale supercomputer across five purpose-built racks, backed by more than 80 MGX manufacturing partners.
The seven chips:
Rubin GPU. TSMC 3nm, multi-chip module, 336 billion transistors. 288GB HBM4 per GPU, 22 TB/s memory bandwidth, 50 petaflops NVFP4 compute. Third-generation Transformer Engine with hardware-accelerated compression. Third-generation Confidential Computing across CPU, GPU, and NVLink domains. Second-generation RAS Engine for real-time health monitoring, fault tolerance, and proactive maintenance.
Vera CPU. 88 custom Olympus cores, Armv9.2, up to 1.5TB LPDDR5X, 1.8 TB/s NVLink-C2C bandwidth. NVIDIA claims 2x efficiency and 50% faster than traditional rack-scale CPUs. The standalone Vera CPU Rack holds 256 CPUs, liquid-cooled, integrated with Spectrum-X Ethernet for reinforcement learning and agentic workloads.
NVLink 6 Switch. Sixth-generation scale-up. 3.6 TB/s per GPU, 260 TB/s all-to-all across the NVL72 rack. More bandwidth than the entire internet, per NVIDIA.
ConnectX-9 SuperNIC. 1.6 Tbps network interface.
BlueField-4 DPU. Storage and security processor. Backbone of the new BlueField-4 STX storage rack and CMX context memory storage platform for KV cache acceleration (see Storage section).
Spectrum-6 Ethernet Switch. World's first co-packaged optics (CPO) switch, now in production. NVIDIA claims 5x optical power efficiency and 10x resiliency versus pluggable transceivers. Process technology co-developed with TSMC. Available in the Spectrum-6 SPX Ethernet Rack with configurable Spectrum-X or Quantum-X800 InfiniBand switches.
Groq 3 LPU. The new addition. More below.

The Vera Rubin NVL72 rack integrates 72 Rubin GPUs and 36 Vera CPUs into a single liquid-cooled unit: 3.6 exaflops of FP4 inference compute, 20.7 TB HBM4, 54 TB LPDDR5X. NVIDIA claims 10x inference token cost reduction and 4x fewer GPUs for MoE training versus Blackwell. Cable-free modular trays. 45-degree hot water cooling. Installation time cut from two days to two hours.
First deployment: Microsoft Azure, which already has the first Vera Rubin NVL72 rack running. Confirmed H2 2026 deployments: AWS, Google Cloud, Microsoft Azure, Oracle Cloud Infrastructure, CoreWeave, Crusoe, Lambda, Nebius, Nscale, and Together AI. System manufacturers: Cisco, Dell, HPE, Lenovo, Supermicro, ASUS, Foxconn, GIGABYTE, Inventec, Pegatron, QCT, Wistron, and Wiwynn.
AWS announced it will deploy more than one million NVIDIA GPUs across its global cloud regions beginning this year, spanning the full stack including Blackwell, Rubin, and Groq 3 LPUs.
Frontier model developers confirmed for Vera Rubin: Anthropic, Meta, Mistral AI, and OpenAI. Dario Amodei, CEO of Anthropic: "NVIDIA's Vera Rubin platform gives us the compute, networking and system design to keep delivering while advancing the safety and reliability our customers depend on." Sam Altman, CEO of OpenAI: "With NVIDIA Vera Rubin, we'll run more powerful models and agents at massive scale."

[02] The Groq Gambit: $20 Billion for a Decode Accelerator
NVIDIA acquired Groq's assets for approximately $20 billion in December 2025, bringing aboard founder Jonathan Ross (formerly of Google's TPU team) and president Sunny Madra. Two months later, the Groq 3 LPU is already in production and integrated into the Vera Rubin stack.

The logic is straightforward. Rubin GPUs are compute-dense: 50 petaflops each, 22 TB/s HBM4 bandwidth. Groq's LPU has modest compute (1.2 petaflops FP8, roughly 1/25th of a Rubin GPU) but carries 500MB of on-chip SRAM running at 150 TB/s, nearly 7x Rubin's memory bandwidth.
NVIDIA's answer: disaggregated inference. Rubin GPUs handle the compute-intensive prefill and attention phases. Groq LPUs handle decode, the bandwidth-limited, latency-sensitive token generation that determines how fast a user sees a response.
The Groq 3 LPX rack holds 256 LPU chips with 128GB on-chip SRAM and 640 TB/s scale-up bandwidth. It sits beside the Vera Rubin NVL72 rack, connected via a custom Spectrum-X interconnect with a low-latency mode that halves network latency between the two systems.
NVIDIA claims the combined system delivers up to 35x higher tokens per second per megawatt versus Blackwell, and up to 10x more revenue opportunity for trillion-parameter models.
Huang's framing was pragmatic. If your workload is mostly high-throughput batch inference, stick with Vera Rubin NVL72. If you need ultra-low-latency token generation for coding assistants or premium agent workflows, add Groq LPX to around 25% of your data centre capacity.
This is a direct course correction. NVIDIA had previously announced a prefill processor called Rubin CPX at its AI Infra Summit. That project appears to have been set aside in favour of Groq's decode-focused architecture.
Ian Buck, NVIDIA's VP of Hyperscale and HPC, confirmed that Groq's LPU does not yet support CUDA natively. It operates as an accelerator to the CUDA stack running on Vera Rubin NVL72. The integration runs through NVIDIA Dynamo, an open-source inference operating system that maps KV cache across thousands of GPUs and routes requests to the best knowledge match to avoid recomputation. NVIDIA claims Dynamo delivered a 30x throughput boost on DeepSeek-R1 on Blackwell. It supports PyTorch, SGLang, TensorRT-LLM, and vLLM. Adoption partners include AWS, Cohere, CoreWeave, Dell, Fireworks, Google Cloud, Lambda, Meta, Microsoft Azure, Nebius, NetApp, OCI, Perplexity, Together AI, and VAST.
Groq 3 LPX ships Q3 2026.
[03] Token Economics: The AI Factory Thesis
Huang spent significant time on what he called "the single most important chart for the future of AI factories." It plots token throughput (vertical axis) against token speed (horizontal axis), both at ISO power. Because every data centre is power-constrained. ServeTheHome's live coverage has the charts.
Tokens are the new commodity. Huang segmented the market into tiers. Free-tier services need high throughput at low cost. Premium services (coding assistants, research agents, real-time reasoning) need high-speed token generation with smart models and long context windows. Price points range from $3 per million tokens at the bottom to $150 per million tokens at the top.
The maths: a one-gigawatt AI factory running Vera Rubin generates 700 million tokens per second. On x86 plus Hopper-era systems, that figure was 0.2 million. A 3,500x increase in two years.
Revenue: if an operator allocates 25% of power to each of four tiers, Vera Rubin generates 5x more revenue than Blackwell from the same power envelope. Add Groq LPX and the multiplier increases at the premium tier. In Huang's words, the token cost is "world-class, basically untouchable." Even if a competing architecture were free, the total cost of ownership would still be higher because a gigawatt data centre costs $40 billion to build regardless of what silicon you put in it.
Huang referenced SemiAnalysis. When he said Blackwell was 35x per watt last year, Dylan Patel accused him of sandbagging. "He's not wrong," Huang said. It was actually closer to 50x.
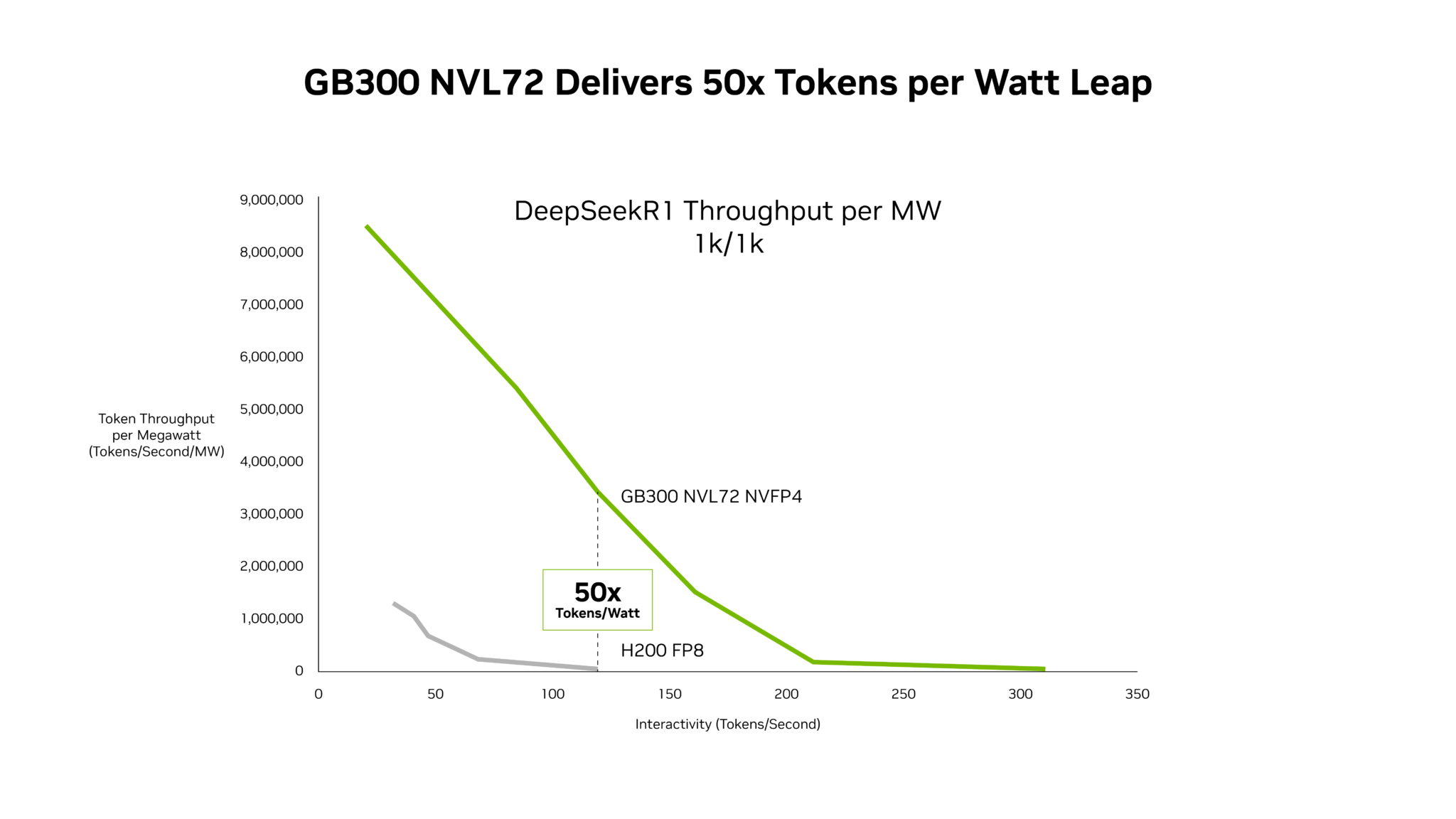
Separately, NVIDIA showed inference providers (Fireworks, Together, and others) growing 100x in the past year. On the same Blackwell hardware, NVIDIA's software updates alone pushed average token speed from roughly 700 tokens per second to nearly 5,000. A 7x improvement from software optimisation on unchanged silicon.
Huang stated his belief that AI compute demand has increased by 1,000,000x in the last two years: a 10,000x increase in compute per task (reasoning, agentic workflows, long-context processing) multiplied by roughly 100x increase in usage.

[04] NemoClaw: The Enterprise Agent Stack
OpenClaw, the open-source agent framework created by Austrian developer Peter Steinberger, is what Huang called "the most popular open source project in the history of humanity." It reached that status in weeks, outpacing what Linux achieved in 30 years (Huang's claim, not independently verified). Steinberger joined OpenAI in February, and OpenClaw moved to an independent foundation.

NVIDIA's response: NemoClaw. An enterprise-grade reference stack built on top of OpenClaw. Installs with a single command. Wraps the agent framework with security, privacy routing, and policy enforcement.
The stack includes OpenShell (open-source safety runtime that sandboxes agents), Nemotron models (pre-integrated), policy engine integration for SaaS compliance, and network guardrails with privacy routing.
Huang's claim: "Every single company in the world needs an OpenClaw strategy." He compared the moment to HTML, Linux, and Kubernetes. Every SaaS company, he said, will become a GaaS company (agents-as-a-service). Every engineer will need an annual token budget. "You're gonna make a few hundred thousand dollars a year, their base pay. I'm going to give them probably half of that on top of it as tokens so that they could be amplified."
Enterprise software platforms integrating NVIDIA's broader Agent Toolkit: Adobe, Atlassian, Amdocs, Box, Cadence, Cisco, Cohesity, CrowdStrike, Dassault Systèmes, IQVIA, Red Hat, SAP, Salesforce, Siemens, ServiceNow, and Synopsys. The AI-Q Blueprint (built with LangChain) tops the DeepResearch Bench accuracy leaderboard, using a hybrid of frontier and open models that cuts query costs in half.
NemoClaw runs on GeForce RTX PCs, DGX Station, and DGX Spark. DGX Spark now supports clustering up to four units into a desktop data centre with near-linear scaling. DGX Station, powered by the GB300 Grace Blackwell Ultra Desktop Superchip, provides 784GB coherent memory and 20 petaflops of AI compute. It can run models up to one trillion parameters. Available from ASUS, Boxx, Dell, HP, and Supermicro from spring 2026.

[05] Open Models: The Nemotron Coalition
NVIDIA announced the Nemotron Coalition, a group collaborating on six families of open frontier models:
Nemotron: language, reasoning, RAG, speech. Nemotron 3 is at the top of multiple benchmarks. Nemotron 3 Ultra positioned as the best open base model. Nemotron 4 in development.
Cosmos: world foundation models for physical AI, video generation, understanding.
Isaac GR00T: general-purpose robotics.
Alpamayo: autonomous vehicle reasoning models. Alpamayo 1.5 downloaded by 100,000+ automotive developers.
BioNeMo: biology, chemistry, molecular design.
Earth-2: weather and climate forecasting.

Coalition members: Black Forest Labs, Cursor, LangChain, Mistral AI, Perplexity, Reflection, Sarvam (India), and Thinking Machines Lab.
Huang committed to a permanent cadence: Nemotron 3 followed by Nemotron 4, Cosmos 1 by Cosmos 2, GR00T by GR00T Generation 2. NVIDIA has invested billions in DGX Cloud supercomputing capacity to train these models.
The play is structural. If every sovereign AI programme, every enterprise fine-tuning pipeline, and every regional model developer starts from a Nemotron base, NVIDIA hardware becomes the default training and serving platform. The models are open. The lock-in is in the silicon.

[06] Autonomous Driving and Physical AI
"The ChatGPT moment of self-driving cars has arrived."

Four new automakers adopting NVIDIA DRIVE Hyperion for Level 4 autonomous vehicles: BYD, Hyundai, Nissan, and Geely. Existing partners include Mercedes-Benz, Toyota, GM, Stellantis, Lucid, Aurora, and Wayve. CNBC coverage here.
Uber partnership expanded: full-stack robotaxis across 28 cities on four continents by 2028, starting with Los Angeles and San Francisco in H1 2027. Target: 100,000 autonomous vehicles in Uber's network. Bolt, Grab, Lyft, and TIER IV are also scaling development on DRIVE Hyperion.
NVIDIA introduced Halos OS, a unified safety architecture for AI-driven vehicles built on ASIL D DriveOS foundations, and the Halos AI Systems Inspection Lab (first accredited lab for AI safety certification; founding members include Bosch, Nuro, Wayve).
On robotics: 110 robots on display at GTC. NVIDIA is working with ABB, Universal Robots, KUKA, Caterpillar, T-Mobile (AI-powered radio towers via Aerial AI-RAN, with Nokia), Disney Research, and Foxconn. The keynote closed with a live demo of an Olaf robot from Frozen, trained using Newton physics simulator and Isaac Lab, walking and talking autonomously on stage.
Roche announced a deployment of 3,500+ Blackwell GPUs across worldwide operations for drug discovery, diagnostics, and manufacturing.
[07] Storage: BlueField-4 STX and Context Memory
A section that got minimal keynote time but carries real operational weight.

NVIDIA launched the BlueField-4 STX storage rack: AI-native storage infrastructure purpose-built for the KV cache demands of agentic AI. The first rack-scale implementation includes the CMX context memory storage platform.
NVIDIA claims: 5x token throughput, 4x energy efficiency, 2x faster data ingestion versus traditional storage. A new framework called DOCA Memos supercharges BlueField-4 with dedicated KV cache processing, boosting inference throughput by up to 5x.
Early adopters: CoreWeave, Crusoe, IREN, Lambda, Mistral AI, Nebius, OCI, and Vultr. Storage partners: Cloudian, DDN, Dell, Everpure, Hitachi Vantara, HPE, IBM, MinIO, NetApp, Nutanix, VAST Data, and WEKA. Manufacturing partners: AIC, Supermicro, QCT.
STX-based platforms available from partners H2 2026.
[08] The Roadmap: Rubin Ultra, Feynman, Space
NVIDIA laid out its silicon roadmap through 2028:
Vera Rubin (shipping H2 2026): NVL72 with copper scale-up. Oberon system maintains backwards compatibility for Blackwell migrations.

Vera Rubin Ultra (2027): introduces the Kyber rack architecture. Compute trays slot vertically, NVLink switches on the back. 144 GPUs in a single NVLink domain. LP35 chip incorporating NVFP4 computing. Optical scale-up via NVLink 576 using CPO switches.
Feynman (2028): new GPU, new LPU (LP40), new CPU called Rosa, BlueField-5, ConnectX-10. Kyber racks with both copper and CPO scale-up. This is the generation where NVIDIA and Groq's LPU architecture merge at a deeper level. WCCFTech has the speculative detail.
Vera Rubin Space Module. Radiation-hardened version for satellite-based AI inference, delivering 25x more compute than previous space-rated H100 GPUs. Partnerships with unnamed aerospace companies are active.

[09] AI Factories: The DSX Platform
NVIDIA announced the DSX platform and the Vera Rubin DSX AI Factory reference design for gigawatt-scale AI factories using Omniverse digital twins:
DSX Air: physical, electrical, thermal, and network simulation. Reduces deployment from months to days.
DSX Flex: makes AI factories grid-flexible assets. NVIDIA claims this unlocks 100 gigawatts of stranded grid power globally.
DSX Max-Q: dynamic power optimisation. NVIDIA claims 30% more AI infrastructure deployable within a fixed-power data centre.
DSX Exchange: operational data platform.
Partners: Siemens, Cadence, Dassault Systèmes, PTC, Jacobs, Procore, Bechtel, Schneider Electric, and Vertiv. NVIDIA is building an AI Factory Research Centre in Virginia to host the first Vera Rubin infrastructure and develop DSX blueprints for multi-generation buildouts.

[10] Data Processing Acceleration
NVIDIA is pushing deep into structured and unstructured data processing with two foundational CUDA X libraries: cuDF (data frames, structured data) and cuVS (vector/semantic data).
IBM is accelerating Watson X.data SQL engines with NVIDIA. Case study: Nestlé runs the same supply chain workload 5x faster at 83% lower cost on GPU-accelerated Watson X.data across 185 countries.
Dell launched the Dell AI Data Platform integrating cuDF and cuVS.
Google Cloud: BigQuery acceleration. Snapchat reduced computing costs by nearly 80% through GPU-accelerated data processing.
The pitch: as AI agents query databases at machine speed, data processing itself becomes a GPU workload. 90% of data generated each year is unstructured. Until now, it has been largely un-queryable. NVIDIA's cuVS uses multimodal AI perception to index unstructured data (PDFs, videos, speech) for the first time at scale.
[11] Cloud and Enterprise Partnerships
The full cloud walkthrough:
Google Cloud: Vertex AI, BigQuery, JAX XLA. Customers: Base10, CrowdStrike, Puma, Salesforce.
AWS: EMR, SageMaker, Bedrock. OpenAI coming to AWS. 1 million+ GPUs deploying 2026.
Microsoft Azure: first to power up Vera Rubin NVL72. AI Foundry, Bing search, Azure regions. Fairwater superfactories scaling to hundreds of thousands of Vera Rubin Superchips.
OCI: NVIDIA was Oracle's first AI customer. Coherent, Fireworks, OpenAI deployed.
CoreWeave: AI-native cloud, first to deploy Vera Rubin.
Palantir: on-prem, air-gapped AI platform deployable in any country using NVIDIA confidential computing.
Together AI: Vera Rubin cloud partner. Maryland facility with B200 GPUs, Memphis facility with GB200/GB300.
Crusoe: confirmed Vera Rubin cloud partner.
Nebius: $2B NVIDIA investment, multiple GW-scale AI factories.

60% of NVIDIA's business comes from the top five hyperscalers. The other 40%: regional clouds, sovereign clouds, enterprise, industrial, robotics, edge, supercomputing.
Industrial software: Cadence, Dassault Systèmes, PTC, Siemens, and Synopsys are building NVIDIA-powered AI agents. Customers: FANUC, HD Hyundai, Honda, JLR, KION, Mercedes-Benz, MediaTek, PepsiCo, Samsung, SK hynix, and TSMC.
Quantum: 35 companies building quantum-GPU hybrid systems with NVIDIA's Quantum platform.
Telecommunications: Aerial AI-RAN partnerships with Nokia and T-Mobile. Base stations reinvented as AI infrastructure platforms running at the edge. Roughly $2 trillion addressable market.
[12] DLSS 5 and Neural Rendering
NVIDIA unveiled DLSS 5, a real-time neural rendering model that fuses generative AI with structured graphics data to produce photorealistic lighting and materials frame by frame.

Huang called it "the GPT moment for graphics." DLSS 5 arrives this autumn with confirmed support from Bethesda, Capcom, Hotta Studio, NetEase, NCSOFT, S-GAME, Tencent, Ubisoft, and Warner Bros. Titles include Assassin's Creed Shadows, Hogwarts Legacy, Phantom Blade Zero, Resident Evil Requiem, Starfield, and The Elder Scrolls IV: Oblivion Remastered.
Neural rendering is the phase Huang has been betting on since NVIDIA introduced RTX ray tracing eight years ago: AI transforming how computer graphics is done. DLSS 5 is the first product to ship on that thesis at scale.
[13] The Numbers That Matter
Financial
$1 trillion: purchase orders for Blackwell and Vera Rubin through 2027 (Huang, keynote)
$215.9 billion: NVIDIA FY2026 revenue; $68.1B in Q4
$20 billion: Groq acquisition (December 2025)
$150 billion: VC investment in AI startups in the last year (largest in human history, per Huang)
Vera Rubin Performance (NVIDIA-claimed, vs Blackwell)
10x: inference token cost reduction
4x: fewer GPUs for MoE training
35x: tokens/sec/MW with Vera Rubin + Groq LPX
10x: more revenue opportunity for trillion-parameter models with Groq LPX
700 million: tokens/sec in a 1GW Vera Rubin factory (up from 0.2M on x86+Hopper)
3.6 exaflops: FP4 inference per NVL72 rack
20.7 TB: HBM4 per NVL72 rack
260 TB/s: NVLink 6 all-to-all per NVL72 rack
Groq 3 LPU
1.2 petaflops FP8 per chip
500 MB SRAM per chip at 150 TB/s
256 LPUs per LPX rack
128 GB SRAM total per LPX rack
640 TB/s scale-up bandwidth per LPX rack
Software/Inference
7x: token speed improvement from software updates alone (700→5,000 tokens/sec on same Blackwell hardware)
30x: Dynamo throughput boost on DeepSeek-R1 on Blackwell
1,000: total CUDA X libraries (100+ new at GTC)
~40 models: announced at GTC
Storage (BlueField-4 STX)
5x: token throughput vs traditional storage
4x: energy efficiency
2x: faster data ingestion
5x: inference throughput with DOCA Memos KV cache processing
DSX AI Factory
30%: more infrastructure deployable within fixed power (Max-Q)
100 GW: stranded grid power unlockable (Flex)
Partnerships
1 million+: NVIDIA GPUs deploying at AWS (2026)
500,000+: NVIDIA GPUs in xAI Colossus 2
1 GW: Thinking Machines Lab Vera Rubin commitment
3,500: Blackwell GPUs in Roche deployment
100,000: target AVs in Uber network by 2028
28 cities: Uber robotaxi footprint by 2028
80+: MGX ecosystem manufacturing partners
GTC 2026
30,000+: attendees from 190+ countries
1,000+: sessions
110: robots on display
20+: press releases
7 chips, 5 racks: Vera Rubin POD system
[14] What Does It All Mean?
Huang framed the two-hour keynote around one idea: the inference inflection has arrived.
Training was the first wave. Inference is now the main event. It drives revenues, it is power-constrained, and it is where the economics of the entire industry are being decided.
The Groq integration is the most significant structural shift.
NVIDIA is no longer building one GPU to rule all workloads.
It is building a system of specialised processors: GPUs for prefill, LPUs for decode, CPUs for orchestration, DPUs for storage, CPO switches for networking. All co-designed to maximise tokens per watt inside a fixed power envelope.
That is a different company to the one that stood on this stage two years ago, and that changes things for key stakeholders across the entire ecosystem:
For operators: Vera Rubin ships H2 2026. Blackwell just became midrange. Anyone locked into long-term Blackwell contracts is one generation behind within months of signing.
For capital allocators: the $1 trillion demand figure either holds and the buildout of the decade continues to accelerate, or it doesn't. NVIDIA's entire product stack, pricing model, and roadmap assumes it holds.
For the supply chain: GTC 2026 confirmed the buildout is not slowing. It is accelerating and specialising. General-purpose data centres are giving way to AI factories engineered at the rack level, simulated in digital twins, optimised per watt for a single output: tokens.
For the GPU audience specifically: the five-rack POD architecture, the BlueField-4 STX storage tier, the DSX factory management layer, and the 30% infrastructure gain from Max-Q power management are the details that will determine who operates profitably in this cycle and who burns cash. The headline is $1 trillion. The real story is in the plumbing.
I'll be covering the individual announcements across the rest of GTC week. If you know someone who should be reading this, send it to them!
Ben
Sources and further reading:
GTC 2026 press releases (16 March 2026):
GTC 2026 week:
Thinking Machines Lab Partnership (9 March)
Nebius $2B Partnership (11 March)
Supporting context (CES 2026, 5 January):
Supporting context (prior):
Uber Robotaxi Partnership (October 2025)
Dynamo Inference Software (May 2025)
Rubin CPX (September 2025)
Third-party (16 March 2026):
Technical deep dives (CES 2026):
Groq acquisition background (December 2025):
OpenClaw background: