

If AI infrastructure feels like wading through an endless sea of acronyms, you’re not alone.
GPUs. CPUs. DPUs. TPUs. It’s like someone decided that progress in computing should be measured by how many TLAs (three-letter acronyms) we can cram into a conversation.
Usually, this newsletter focuses on company profiles or weekly rundowns of the latest trends in GPU computing, hyperscalers, and AI hardware investments.
However, those formats only take you so far in navigating this growing and complex ecosystem.
Today, we’re trying something different: a long-form deep dive into the 24 types of processors shaping AI infrastructure today. Think of it as your excessively long cheat sheet. Each processor gets its moment in the spotlight, with clear explanations of its purpose, architecture, benefits, drawbacks, and use cases.
Why am I doing this?
Because AI is complicated enough without having to memorise what an NPU does versus an IPU.
By this end, you’ll have a surface-level understanding of the entire processor landscape. No, it’s not everything you could ever know about these chips (that would be a book, not a newsletter). But it’s enough to help you understand the acronyms and their roles in powering AI innovation.
This is the first of what will likely be many long-form guides to support you as you navigate this ever-expanding industry.
So, let’s dive in.
The GPU Audio Companion Issue #8
Want the GPU breakdown without the reading? The Audio Companion does it for you—but only if you’re subscribed. Fix that here.
Table of Contents
1. GPU (Graphics Processing Unit)
Specialised processors designed for handling parallel computations, initially for graphics rendering but now critical in AI and ML workloads.
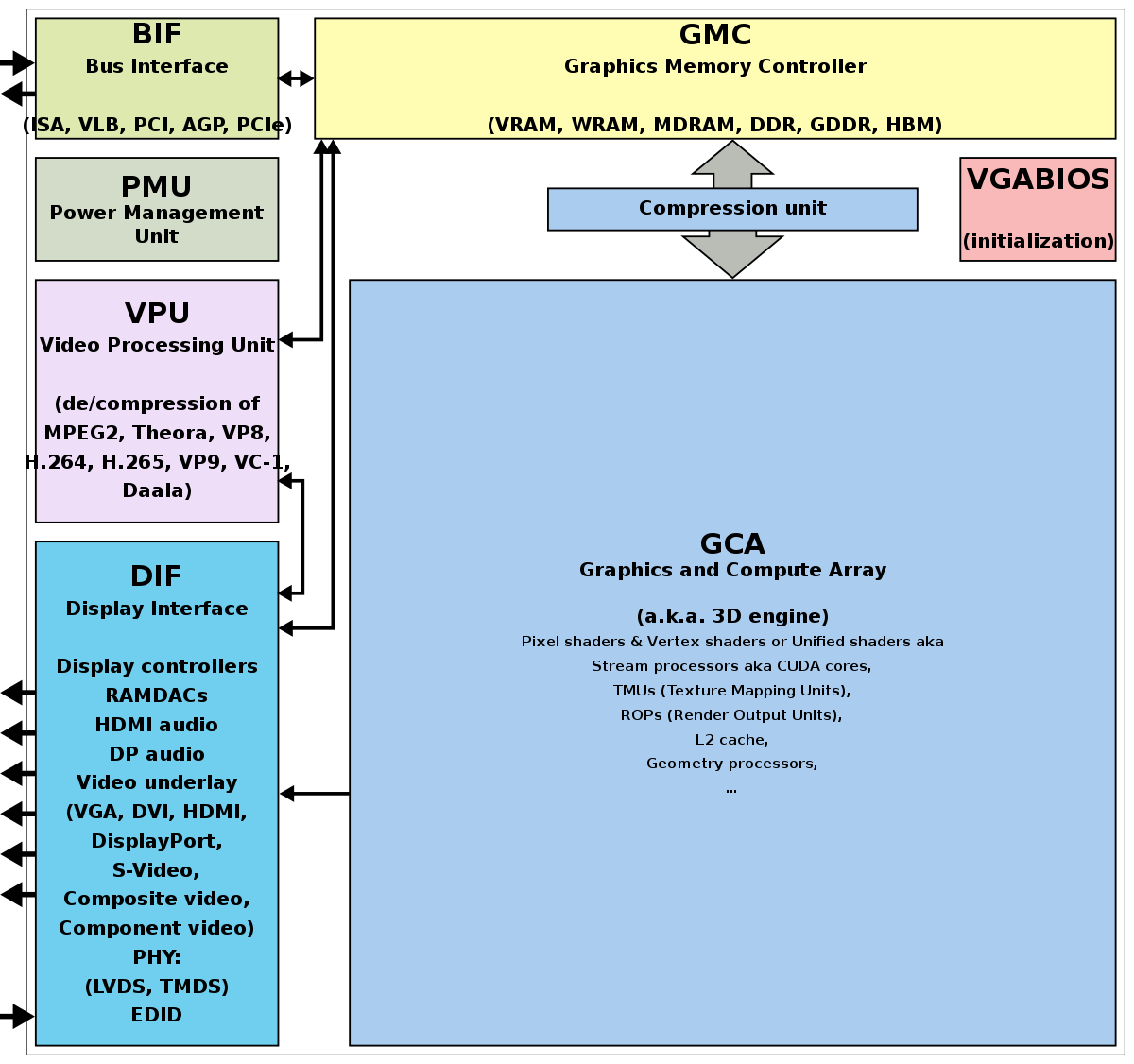
Architecture
Core Design: Thousands of cores in SIMD (Single Instruction, Multiple Data) or SIMT (Single Instruction, Multiple Threads) architecture.
Memory: High-bandwidth memory (HBM/GDDR) ensures rapid data transfer between cores.
Thread Management: Threads grouped into warps (NVIDIA) or wavefronts (AMD), ensuring efficient execution of parallel tasks.
Why the Architecture Is That Way
GPUs are optimised for the parallelism inherent in graphical rendering and matrix operations, making them ideal for deep learning and scientific computations.
Benefits
Massive parallelism; processes large volumes of computations simultaneously.
Scalability; supports large AI models and GPU clusters for distributed workloads.
Versatility; suitable for gaming, video rendering, and simulation in addition to AI and ML workloads.
Drawbacks
High cost; expensive compared to other processors.
Energy consumption; significant power requirements, especially in large clusters.
Limited efficiency for sequential tasks; not ideal for workloads requiring high single-threaded performance.
Use Cases
Training and inference for deep learning models.
Gaming and 3D rendering.
High-performance scientific simulations.
Companies
Key Takeaway
GPUs remain the backbone of AI and ML workloads due to their unparalleled parallel processing capabilities, despite their high cost and energy demands.
2. CPU (Central Processing Unit)
General-purpose processors designed to execute sequential tasks and manage overall system operations.

Architecture
Core Design: Few but powerful cores with multithreading capabilities (e.g., Intel Hyper-Threading).
Instruction Pipeline: Deep pipelines allow high clock speeds and out-of-order execution.
Cache Hierarchy: Multi-level caches (L1, L2, L3) reduce latency by storing frequently accessed data close to the processor.
Why the Architecture Is That Way
CPUs are built for versatility, capable of running diverse workloads, from operating systems to applications requiring high responsiveness.
Benefits
Versatility; supports a wide range of applications and tasks.
Latency Efficiency; optimised for sequential workloads and fast responses.
Broad Compatibility; compatible with nearly all types of software.
Drawbacks
Limited parallelism; struggles to match GPUs for tasks requiring massive parallelism.
Scalability challenges; not ideal for scaling large AI workloads.
Use Cases
Managing operating systems and software applications.
Orchestrating and supporting other hardware components in a system.
Light AI workloads, such as small-scale inference tasks.
Companies
Key Takeaway
CPUs are indispensable for general-purpose computing and system management, offering versatility and broad compatibility but falling short in handling highly parallel AI tasks.
3. TPU (Tensor Processing Unit)
Custom accelerators optimised for deep learning tasks, particularly TensorFlow operations.

Architecture
Matrix Units: Uses systolic arrays for efficient matrix multiplication.
In-Memory Compute: Minimises latency by reducing data transfer.
Streamlined Instruction Set: Focuses exclusively on tensor operations, enabling high efficiency.
Why the Architecture Is That Way
TPUs are purpose-built for deep learning, focusing on matrix-heavy operations like those in neural networks, particularly within Google’s TensorFlow ecosystem.
Benefits
Energy efficiency; highly optimised for AI workloads, reducing power consumption compared to GPUs.
High throughput; processes tensors at exceptional speed.
Integration; seamlessly integrated with Google Cloud and TensorFlow workflows.
Drawbacks
Limited flexibility; proprietary to Google Cloud and TensorFlow-centric.
Niche use case; less versatile than GPUs for broader AI workloads.
Use Cases
Training and inference of deep learning models within Google Cloud.
Optimising TensorFlow pipelines.
Large-scale AI services.
Companies
Key Takeaway
TPUs offer remarkable efficiency and speed for TensorFlow-based deep learning tasks but are limited by their proprietary nature and narrower focus compared to more versatile processors like GPUs.
4. DPU (Data Processing Unit)
Specialised processors designed to handle data-centric tasks such as networking, storage, and security, offloading these operations from the CPU to improve system efficiency.

Architecture
Programmable Multicore CPUs: Designed to optimise data flow and manage compute-heavy tasks.
Networking Acceleration: Integrates features like RDMA (Remote Direct Memory Access) and NVMe over Fabric.
Security Modules: Includes on-chip cryptographic engines for secure data transfers.
Virtualisation Support: Enables hardware-accelerated software-defined infrastructure.
Why the Architecture Is That Way
DPUs address bottlenecks in data-intensive environments by offloading tasks that would otherwise burden CPUs, enabling more efficient resource usage in hyperscale cloud environments.
Benefits
Improved system efficiency; offloads storage, networking, and security tasks.
Enhanced security; dedicated cryptographic hardware for data protection.
High data throughput; speeds up I/O operations, crucial for AI pipelines.
Scalable; essential for hyperscale, cloud, and edge computing environments.
Drawbacks
Specialised role; limited to data processing tasks; cannot replace general-purpose processors.
Infrastructure complexity; adds operational overhead and cost.
Use Cases
Cloud data centres requiring efficient data management.
AI pipelines requiring optimised storage and data movement.
Network-intensive applications like software-defined networking (SDN).
Companies
Key Takeaway
DPUs enhance data centre efficiency by offloading specialised tasks from CPUs, making them vital for large-scale and data-intensive AI applications, albeit with added complexity and cost.
5. LPU (Language Processing Unit)
Specialised processors developed by Groq optimised for ultra-low-latency, high-throughput AI tasks.
Architecture
Deterministic Execution: Guarantees predictable performance by avoiding speculative execution.
Stateless Design: Simplifies the execution pipeline, eliminating dependencies between instructions.
Parallelism: Leverages instruction-level parallelism to maximise throughput.
Why the Architecture Is That Way
LPUs are purpose-built for real-time AI inference, where deterministic, low-latency performance is crucial for safety-critical systems like autonomous vehicles.
Benefits
Predictable performance; ensures consistent response times, critical for real-time systems.
High throughput; optimised for processing large inference workloads efficiently.
Scalability; easily deployed in distributed AI inference environments.
Drawbacks
Niche focus; primarily suited for inference, not training or general-purpose computing.
High cost; initial setup and integration can be expensive.
Use Cases
Real-time inference in autonomous vehicles and robotics.
Large-scale AI inference workloads in hyperscale environments.
Applications requiring strict latency guarantees, like medical imaging.
Companies
Key Takeaway
LPUs deliver exceptional performance for real-time AI inference tasks, making them ideal for applications where latency and predictability are paramount, despite their high costs and specialised focus.
6. ASIC (Application-Specific Integrated Circuit)
Custom-designed chips built for a single, specific task, offering maximum efficiency and performance for dedicated applications such as AI inference or cryptocurrency mining.

Architecture
Fixed Logic Design: Tailored to perform a single function with minimal overhead.
Optimised Data Path: Custom circuitry ensures the fastest possible execution for the target workload.
Compact Layout: Reduces chip area, improving power efficiency and scalability.
Why the Architecture Is That Way
ASICs sacrifice flexibility for performance, focusing entirely on the target application to achieve unmatched speed and efficiency.
Benefits
Ultra-high efficiency; delivers the best performance and energy efficiency for dedicated workloads.
Compact and scalable; smaller silicon area reduces power and cooling requirements, making them ideal for hyperscale deployments.
Longevity for single use cases; once deployed, ASICs can run the same task with consistent performance over time.
Drawbacks
Inflexibility; cannot be reprogrammed or repurposed for other tasks.
High initial cost; expensive and time-intensive to design and manufacture.
Limited applicability; only viable for high-volume, repetitive tasks.
Use Cases
AI inference at scale in hyperscale data centres.
Cryptocurrency mining, such as Bitcoin.
Dedicated systems in consumer electronics, such as video encoding or network routing.
Companies
Cerebras (Wafer-scale engines - not strictly an ASIC, but ASIC-like)
Key Takeaway
ASICs provide unparalleled efficiency and performance for specific tasks, making them indispensable for large-scale, repetitive applications, though their lack of flexibility and high initial costs limit their broader use.
7. FPGA (Field-Programmable Gate Array)
Flexible, reconfigurable chips that can be programmed post-manufacture to perform various tasks, making them ideal for prototyping and niche AI applications.

Architecture
Configurable Logic Blocks (CLBs): Versatile building blocks connected by programmable interconnects.
Memory Blocks: Embedded distributed memory for custom data handling.
Parallel Processing Fabric: Supports high-performance concurrency for specialised tasks.
Why the Architecture Is That Way
FPGAs are designed to provide maximum flexibility, enabling developers to optimise the architecture for specific tasks without needing new hardware.
Benefits
Customisable; reconfigurable to suit evolving workloads or specialised applications.
Efficient for real-time processing; low latency for specific tasks like high-frequency trading.
Rapid prototyping; ideal for testing new AI models or systems before committing to ASIC development.
Drawbacks
Programming complexity; requires significant expertise to configure and optimise.
Lower efficiency; not as power-efficient as ASICs for fixed workloads.
Costly for large deployments; higher per-unit costs compared to ASICs.
Use Cases
Prototyping AI models and custom hardware designs.
Edge computing in industrial IoT systems.
High-frequency trading systems requiring ultra-low latency.
Companies
Key Takeaway
FPGAs offer unparalleled flexibility for custom and evolving AI applications, making them perfect for prototyping and specialised tasks, though their complexity and cost can be barriers to large-scale deployments.
8. NPU (Neural Processing Unit)
Dedicated processors designed to accelerate neural network inference, particularly in edge and mobile devices.
Architecture
Neural-Specific ALUs: Specialised arithmetic units for AI tasks like convolutions, activations, and pooling.
Compression Techniques: Reduces memory and bandwidth usage for compact, efficient processing.
Integrated Accelerators: Enhances speed and efficiency for inference-specific tasks.
Why the Architecture Is That Way
NPUs are tailored to meet the growing demand for AI inference in resource-constrained environments like mobile and IoT devices.
Benefits
Energy efficiency; low power consumption, ideal for battery-powered devices.
Compact design; fits seamlessly into mobile and embedded systems.
Real-time performance; handles on-device AI tasks like facial recognition and AR without reliance on cloud computing.
Drawbacks
Limited versatility; primarily designed for inference, not training or other AI tasks.
Restricted compute power; less capable than GPUs or TPUs for large-scale AI workloads.
Use Cases
On-device AI for smartphones, tablets, and wearables.
Smart cameras and edge devices in IoT systems.
Augmented reality (AR) and virtual reality (VR) applications.
Companies
Key Takeaway
NPUs are essential for enabling efficient and real-time AI processing on edge devices, offering low power consumption and compact designs, though they are limited in handling more extensive AI tasks compared to larger processors.
9. QPU (Quantum Processing Unit)
Processors that harness the principles of quantum mechanics to solve problems infeasible for classical processors, often achieving exponential speedups in niche areas like optimisation and cryptography.

Architecture
Qubits: Quantum bits represent data in superposition, enabling simultaneous computation across multiple states.
Quantum Gates: Perform operations like entanglement, superposition, and quantum teleportation.
Cryogenic Infrastructure: Operates at near-absolute-zero temperatures to maintain quantum coherence.
Why the Architecture Is That Way
Quantum processors leverage quantum properties to explore exponentially larger problem spaces, making them ideal for complex, high-dimensional computations.
Benefits
Exponential speedups; solves specific problems much faster than classical systems.
Specialised applications; ideal for cryptography, optimisation, and molecular simulations.
Scalable potential; future advancements may unlock broader AI applications.
Drawbacks
Experimental stage; limited real-world deployment and reliability.
High cost; requires expensive infrastructure and maintenance.
Complex ecosystem; difficult to integrate with existing AI workflows.
Use Cases
Optimising large-scale supply chain or logistics networks.
Simulating quantum systems in physics and chemistry.
Developing next-generation cryptographic algorithms.
Companies
Key Takeaway
QPUs hold transformative potential for solving complex problems beyond the reach of classical processors, though their experimental nature and high costs currently limit widespread adoption.
10. DSP (Digital Signal Processor)
Specialised processors built for real-time processing of audio, video, and communication signals, prioritising low latency and deterministic performance.

Architecture
Multiply-Accumulate Units (MACs): Efficiently handle repetitive mathematical operations common in signal processing.
Pipelined Architecture: Ensures rapid execution of sequential signal-processing tasks.
Energy Efficiency: Optimised for low-power operation in mobile and embedded systems.
Why the Architecture Is That Way
DSPs are tailored to handle deterministic, repetitive computations required for real-time signal processing.
Benefits
Real-time performance; processes audio, video, and communication signals with low latency.
Low power consumption; optimised for mobile and embedded environments.
Dedicated processing units; efficiently execute specialised signal tasks.
Drawbacks
Limited versatility; not suited for general-purpose or AI-heavy tasks.
Niche use cases; primarily relevant for signal processing domains.
Use Cases
Audio encoding and decoding in mobile devices.
Real-time video compression for streaming platforms.
Signal processing in telecommunications and networking.
Companies
Key Takeaway
DSPs excel in handling real-time signal processing tasks with low latency and power consumption, making them ideal for mobile and embedded applications, though their specialisation limits their use in broader AI tasks.
11. IPU (Intelligence Processing Unit)
Processors from Graphcore designed for highly complex and irregular computations in AI workloads, excelling in training large-scale models with high parallelism and low latency.
Architecture
Fine-Grain Parallelism: Thousands of independent cores enable highly parallel workloads.
Distributed Memory Architecture: High-speed interconnects and local memory provide rapid data access.
Graph-Centric Design: Optimised for computations in graph-based AI models like neural networks.
Why the Architecture Is That Way
IPUs are built to handle the irregular and dynamic data flows typical of AI models, particularly those requiring parallelism and frequent memory access.
Benefits
Efficient for irregular data; handles graph workloads like neural networks and recommendation systems.
Scalability; performs well across distributed training environments.
Optimised for AI research; tailored for experimental and advanced AI models.
Drawbacks
Niche focus; primarily suited for research and graph-based AI tasks.
High initial investment; expensive to deploy and maintain.
Use Cases
Training graph neural networks (GNNs) and large language models.
AI research focusing on novel architectures and workloads.
Advanced recommendation systems in e-commerce.
Companies
Key Takeaway
IPUs offer exceptional performance for complex and irregular AI workloads, making them ideal for advanced research and large-scale model training, though their specialised nature and high costs limit broader application.
12. RPU (Reconfigurable Processing Unit)
A hybrid processor combining characteristics of FPGAs and ASICs, enabling reconfigurability while achieving near-ASIC efficiency.
Architecture
Reconfigurable Logic: Combines programmable logic blocks for adaptability.
Integrated Memory Blocks: Reduces latency by keeping data close to compute resources.
Parallelism: Supports diverse workloads dynamically by reconfiguring logic paths.
Why the Architecture Is That Way
RPUs combine flexibility with high performance, catering to applications where workloads evolve or require fine-tuning after deployment.
Benefits
Adaptable to changing AI workloads; reduces the need for hardware redesigns.
Excellent for rapid prototyping and iterative development.
More efficient than FPGAs for long-term deployment.
Drawbacks
More expensive than fixed-function ASICs.
Complex to program, requiring specialised knowledge.
Performance still trails behind ASICs for static workloads.
Use Cases
Evolving AI models in dynamic environments.
AI research where workloads are constantly refined.
Deployment in industrial systems requiring periodic updates.
Companies
Key Takeaway
RPUs provide a versatile and efficient solution for dynamic AI environments, offering a balance between flexibility and performance, though they come with higher costs and programming complexity than fixed-function processors.
13. NMP (Neuro-Morphic Processor)
Processors inspired by the human brain, using spiking neural networks (SNNs) to emulate biological neuron behaviour.
Architecture
Event-Driven Design: Only consumes power when computation is needed.
Spiking Neural Networks: Processes information in bursts, akin to biological neurons firing.
Energy Efficiency: Designed with minimal power consumption in mind, prioritising edge applications.
Why the Architecture Is That Way
Neuromorphic processors aim to deliver real-time performance while consuming minimal energy, making them ideal for applications requiring continuous sensory input processing.
Benefits
Extremely energy efficient, suitable for battery-powered devices.
Performs Exceptionally Well for Event-Driven AI Workloads.
Can Handle Sensory and Environmental Data in Real Time.
Drawbacks
Limited compatibility with mainstream deep learning frameworks.
Best suited for niche applications, limiting broad adoption.
Still in experimental stages, with minimal large-scale deployment.
Use Cases
Robotics with real-time environmental sensing.
IoT devices requiring low-power, always-on processing.
Sensory systems in healthcare, such as auditory or visual aids.
Companies
Key Takeaway
Neuromorphic processors offer groundbreaking energy efficiency and real-time processing capabilities inspired by the human brain, making them ideal for specialised applications. However, their early development stage and limited compatibility hinder widespread use.
14. RDU (Reconfigurable Data Unit)
An advanced AI processor developed by SambaNova Systems. Built for adaptability, RDUs dynamically scale and adjust to meet the demands of distributed AI workloads, offering high performance for training and inference with flexible data management.

Architecture
Reconfigurable Logic Blocks: Programmable elements that adjust data processing paths to optimise specific AI tasks.
Integrated Memory Management: High-bandwidth memory interfaces and controllers reduce latency and ensure rapid data movement.
High-Speed Interconnects: Facilitate fast communication between RDUs, enabling efficient scaling across distributed systems.
Energy-Efficient Design: Incorporates advanced power management for performance optimisation in power-constrained deployments.
Why the Architecture Is That Way
Traditional processors often struggle with the dynamic and fluctuating nature of AI workloads, creating inefficiencies. RDUs are designed to handle this variability by integrating reconfigurable logic and advanced data management, allowing them to adapt to different AI tasks, optimise resource use, and maintain consistent performance in distributed environments.
Benefits
Seamlessly scales to accommodate fluctuating AI workloads.
Can be tailored for specific tasks without requiring new hardware.
Strong performance per watt, suitable for large-scale deployments with power constraints.
Drawbacks
Advanced features come with a premium price tag.
Requires sophisticated hardware and software configurations, increasing development time.
Optimising and deploying RDUs effectively demands expertise, which may limit accessibility.
Use Cases
Accelerates training times for large-scale models across multiple nodes.
Offers flexible, scalable compute power for AI-as-a-Service platforms.
Supports dynamic inference tasks like recommendation engines and real-time analytics.
Companies
Key Takeaway
RDUs are a flexible and scalable solution for managing diverse AI workloads in distributed environments. By combining reconfigurable architecture with advanced data management, they deliver high performance and energy efficiency. While complex and costly to implement, their adaptability makes them a valuable tool for large-scale AI systems and cloud-based platforms.
15. Systolic Array Processors
Specialised processors designed for matrix-heavy workloads, foundational to neural network computations.
Architecture
Fixed Dataflow: Predefined sequences of operations optimise matrix multiplications.
Compute-in-Memory Integration: Minimises data movement between compute units and memory.
Highly Parallel Design: Multiple units work simultaneously on tensor operations.
Why the Architecture Is That Way
Neural networks are built on matrix multiplications, and systolic arrays deliver unmatched efficiency for these repetitive, structured computations.
Benefits
Exceptional throughput for AI training and inference.
Energy-efficient compared to general-purpose processors.
Highly optimised for structured tensor operations.
Drawbacks
Limited versatility for non-matrix-based tasks.
Best suited for specific deep learning applications, not general-purpose AI workloads.
Can be costly to integrate into diverse pipelines.
Use Cases
Training large-scale language models and image recognition systems.
AI inference pipelines with consistent workloads.
Hyperscale environments demanding high throughput for specific tasks.
Companies
Key Takeaway
Systolic array processors excel in handling structured matrix operations essential for neural networks, providing high efficiency and throughput for specific AI tasks, though their specialised nature limits broader applicability.
16. VPU (Vision Processing Unit)
Processors optimised for computer vision workloads, including object detection, image recognition, and augmented reality (AR).
Architecture
Specialised Vision Cores: Optimised for convolutional neural networks (CNNs).
Integrated Accelerators: Speed up specific vision tasks like feature extraction.
Low Latency Pipelines: Tailored for real-time image processing.
Why the Architecture Is That Way
Vision tasks require processing vast amounts of pixel data quickly and efficiently, and VPUs are designed to deliver high performance without draining power.
Benefits
Excellent for real-time vision applications in AR/VR and robotics.
Low power consumption, making them ideal for edge devices.
Highly efficient for CNN (convolutional neural network)-based Workloads.
Drawbacks
Limited utility outside vision-related tasks.
Can struggle with workloads requiring significant general-purpose computing.
Use Cases
Autonomous vehicles and drones requiring object detection and collision avoidance.
AR/VR systems for real-time rendering and tracking.
Robotics with visual navigation and scene understanding.
Companies
Key Takeaway
VPUs are specialised for computer vision tasks, providing high efficiency and low power consumption for real-time applications, though their focus on vision limits their use in broader AI tasks.
17. Accelerators for In-Memory Computing (PIM - Processing-In-Memory)
Processors that integrate computation directly within memory cells to eliminate data movement bottlenecks and improve efficiency.
Architecture
Memory-Centric Design: Performs computation within memory arrays to minimise data transfer overhead.
Parallelised Memory Access: Enables simultaneous computations across multiple memory cells.
Custom Logic Integration: Adds processing elements to DRAM or SRAM, creating hybrid compute-memory units.
Why the Architecture Is That Way
The traditional separation of memory and processing units causes significant latency and power inefficiency. PIM accelerators address this by moving computation closer to data, solving the "von Neumann bottleneck."
Benefits
Dramatically reduces latency and energy consumption.
Improves throughput for memory-intensive AI tasks like inference.
Efficient for workloads with high data locality, such as neural networks.
Drawbacks
Limited availability and adoption due to experimental Status.
Not as versatile for general-purpose computing.
Requires custom software stacks to leverage its architecture.
Use Cases
AI inference pipelines where energy efficiency is critical.
Embedded systems in IoT devices needing localised processing.
Real-time analytics in edge devices, such as security cameras or industrial sensors.
Companies
Key Takeaway
PIM accelerators offer significant improvements in latency and energy efficiency for memory-intensive AI tasks by integrating computation within memory, though their experimental status and specialised nature limit current adoption.
18. SoC (System-on-Chip)
Integrated circuits combining multiple processors, such as CPUs, GPUs, and NPUs, into a single compact chip for energy-efficient systems.

Architecture
Multi-Processor Integration: Includes diverse components like CPUs, GPUs, NPUs, and memory controllers in one package.
Specialised Subsystems: Incorporates AI accelerators, DSPs, and I/O controllers for task-specific optimisation.
Unified Memory: Shared memory architecture reduces data movement latency.
Why the Architecture Is That Way
SoCs are designed to deliver compact, power-efficient solutions for edge devices and mobile systems, where size and energy constraints are critical.
Benefits
All-in-one solution for edge AI and mobile applications.
Optimised for energy efficiency and low power consumption.
Compact design reduces hardware complexity and cost.
Drawbacks
Limited scalability for hyperscale AI workloads.
Fixed design limits flexibility for major hardware changes.
Use Cases
Smartphones and tablets with integrated AI capabilities.
Edge devices in smart homes or industrial IoT.
Robotics and drones requiring lightweight processing power.
Companies
Key Takeaway
SoCs provide a highly integrated and energy-efficient solution for mobile and edge AI applications, consolidating multiple processing units into a single chip, though they are not suited for large-scale AI workloads.
19. Optical Chips
Processors using photons instead of electrons to process data, offering unparalleled bandwidth and energy efficiency for AI workloads.
Architecture
Photon-Based Data Transfer: Uses light to transmit and compute data, minimising electrical resistance.
Integrated Photonic Circuits: Combines optical components like waveguides and lasers on a single chip.
Hybrid Optical-Electrical Systems: Incorporates traditional electronic processing for tasks requiring logic gates.
Why the Architecture Is That Way
Optical chips solve the energy and bandwidth limitations of traditional processors by leveraging light's speed and efficiency.
Benefits
Extremely high bandwidth, ideal for hyperscale AI workloads.
Energy-efficient compared to electronic-only processors.
Scalable for data centres and large neural networks.
Drawbacks
Experimental and expensive, with limited commercial deployment.
Requires hybrid systems for compatibility with traditional hardware.
Use Cases
AI training workloads with massive data requirements.
Data centres optimising for low power consumption.
Scientific computing requiring high-speed simulations.
Companies
Key Takeaway
Optical chips offer groundbreaking bandwidth and energy efficiency for large-scale AI applications by utilising photonics, though their experimental status and high costs currently limit widespread adoption.
20. Analogue Chips
Chips that use continuous signals to compute, mimicking natural processes for energy-efficient AI workloads.

Architecture
Analogue Signal Processing: Processes data in continuous waves rather than discrete bits.
Neuromorphic Features: Incorporates designs inspired by biological systems.
Integrated Memory and Compute: Reduces energy use by combining computation with storage.
Why the Architecture Is That Way
Analogue chips focus on efficiency, targeting applications where approximate results are acceptable, such as AI inference.
Benefits
Significantly lower power consumption compared to digital chips.
Faster computation for certain workloads due to reduced data conversions.
Ideal for edge devices with energy constraints.
Drawbacks
Limited precision compared to digital processors.
Compatibility challenges with existing digital ecosystems.
Still in early development stages.
Use Cases
AI inference in IoT devices and wearables.
Real-time environmental monitoring systems.
Autonomous systems prioritising energy efficiency.
Companies
Key Takeaway
Analogue chips provide highly energy-efficient processing by emulating natural signals, making them suitable for specific AI inference tasks, though their limited precision and compatibility challenges hinder broader use.
21. SPU (Secure Processing Unit)
Specialised processors designed to handle cryptographic operations, ensuring secure data transfer and storage.

Architecture
Hardware Cryptography Engines: Optimised for encryption and decryption tasks.
Secure Key Management: Provides tamper-proof storage and handling of cryptographic keys.
Isolated Processing Zones: Creates secure execution environments for sensitive operations.
Why the Architecture Is That Way
With growing concerns over data breaches, SPUs are built to ensure secure processing without compromising performance.
Benefits
Enhances security for sensitive data.
Reduces computational load on CPUs and general-purpose processors.
Ensures compliance with stringent security regulations.
Drawbacks
Limited to cryptographic tasks; not suitable for general-purpose computing.
Adds complexity and cost to system design.
Use Cases
Financial transactions requiring real-time encryption.
Secure boot processes in mobile devices and IoT.
Healthcare systems managing sensitive patient data.
Companies
Key Takeaway
SPUs are essential for securing data through specialised cryptographic processing, ensuring high security for sensitive applications, though their focus on security tasks limits their use in general computing scenarios.
22. XPU (Heterogeneous Processing Unit)
A catch-all term for architectures combining CPUs, GPUs, and other accelerators to create unified systems optimised for diverse workloads.

Architecture
Heterogeneous Design: Combines different processor types on a unified platform.
Unified Memory Architecture: Reduces latency by enabling seamless data sharing.
Dynamic Task Allocation: Assigns workloads to the most appropriate processor.
Why the Architecture Is That Way
XPUs address the increasing diversity of AI workloads, providing flexibility to handle tasks ranging from data preprocessing to inference.
Benefits
Extremely versatile, suitable for varied AI and data workloads.
Reduces the need for multiple, separate systems.
Optimises performance across different tasks.
Drawbacks
Complex to program and optimise.
Higher upfront costs for hardware integration.
Use Cases
AI-as-a-Service platforms managing mixed workloads.
Data centres consolidating diverse processing needs.
Enterprise systems requiring flexibility in AI and analytics.
Companies
Key Takeaway
XPUs provide a unified and flexible processing solution for diverse AI workloads, enhancing efficiency and performance across various tasks, though their complexity and cost can be challenging for implementation.
23. XDU (3.5D Extreme Data Unit)
Advanced interconnect technologies combining compute and memory at high density, enabling extreme data bandwidth for AI workloads.
Architecture
3.5D Packaging: Integrates compute and memory through advanced packaging technologies for reduced latency.
Extreme Bandwidth: Provides high-speed data movement across densely packed modules.
Thermal Management Systems: Manages heat dissipation in high-performance systems.
Why the Architecture Is That Way
XDUs are designed to address the growing data bandwidth requirements of AI, particularly for memory-intensive tasks like model training.
Benefits
Exceptional bandwidth for data-intensive AI tasks.
Reduces latency and bottlenecks in memory access.
Compact design simplifies large-scale deployment.
Drawbacks
High development and deployment costs.
Requires advanced cooling solutions due to heat generation.
Use Cases
AI training for large-scale language and vision models.
Data centers with memory-heavy workloads.
High-performance computing in scientific research.
Companies
Key Takeaway
Broadcom’s XDUs deliver outstanding data bandwidth and reduced latency for memory-intensive AI tasks, making them ideal for large-scale training and high-performance computing, though their high costs and cooling requirements present significant challenges.
24. TCP (Tensor Contraction Processor)
Specialised processors that preserve the native tensor structure of AI workloads to deliver greater data reuse and easier optimisation while using less energy.
Architecture
Tensor-Native Design: Directly processes tensors as fundamental datatypes, rather than flattening tensors to matrices for operations like matmul.
Unified Memory Access and High-Bandwidth Interconnect: Efficiently manages memory access patterns, and facilitates rapid data transfer.
Flexible Array Design and Scalable Architecture: Dynamically adapts to different tensor sizes and shapes to deliver efficient processing of a wider range of inference workloads, and facilitates deployments across multiple cards for larger workloads.
Why the Architecture Is That Way
TCPs are designed to accelerate tensor contractions, the core operation in AI workloads. Preserving tensor structure allows for optimised memory access and computation while maximising throughput and minimising latency.
Benefits
Optimised specifically for tensor contraction and co-designed with a general compiler.
Reduced data movement lowers power consumption and delivers greater tokens/watt.
Maintains high throughput and low latency across variable batch sizes.
Drawbacks
Designed solely for deploying and fine-tuning models.
Cannot be used in model training.
Use Cases
Accelerating a wide variety of AI models, including language models, multimodal models, reasoning models and Agentic AI.
Lowering OpEx through reduced energy consumption and simplified cooling needs.
AI workload execution in low-density and non-AI-specific data centre facilities.
Companies
Key Takeaway
TCPs AI native architecture can substantially reduce inference costs while still providing exceptional programmability and performance at a much lower power level, though they are only suited for inference workloads.
Conclusion: Your Go-To AI Processor Cheat Sheet
So, there we have it.
24 processors. Each with quirks, strengths, and roles in the AI world. From GPUs driving deep learning to XDUs pushing memory integration to the limit, we’ve covered a lot of ground.
The takeaway?
If this alphabet soup is anything to go by, the future of AI hardware is both diverse and specialised.
This is a deviation from our usual format of company profiles or weekly rundowns, but the reason is simple: navigating this ecosystem requires more than bite-sized updates. Today’s guide is the first of many long-form pieces designed to help you understand the hardware driving AI innovation. The goal wasn’t to turn you into a chip designer or a quantum physicist. It was to give you an approachable guide to understanding the processors powering AI.
Whether you’re building the next big project or simply trying to stay ahead in a complex field, you now have a resource to cut through the noise.
The next big breakthrough, with its inevitable TLA, is already on the horizon. When it arrives, we’ll be here to break it down.
For now, go forth and conquer AI hardware with confidence.
Or, at least impress someone by casually explaining the difference between a TPU and an RPU. (Trust me, they’ll ask.)
Keep The GPU Sharp and Independent
Good analysis isn’t free. And bad analysis? That’s usually paid for.
I want The GPU to stay sharp, independent, and free from corporate fluff. That means digging deeper, asking harder questions, and breaking down the world of GPU compute without a filter.
If you’ve found value in The GPU, consider upgrading to a paid subscription or supporting it below:
☕ Buy Me A Coffee → https://buymeacoffee.com/bbaldieri
It helps keep this newsletter unfiltered and worth reading.